

什么是机器学习?
机器学习起源于统计学和数学,是人工智能的一个重要分支,它可以让计算机自动学习一类数据中的规律,通过机器学习可以从已知的数据中找出规律,预测未来的数据。
机器学习作为一种函数
在冰淇淋销售场景中,我们的目标是训练一个可以根据天气预测冰淇淋销售数量的模型。 当天的天气测量值(温度、降雨量、风速等)是特征 (x),每日售出的冰淇淋数量是标签 (y)。
在医疗场景中,目标是根据患者的临床测量值预测患者是否有患糖尿病的风险。 患者的测量值(体重、血糖水平等)是特征 (x),患糖尿病的可能性(例如,1 表示有风险,0 表示没有风险)是标签 (y)。
- 摘自Microsoft Learn
正如以上所说,机器学习是一种函数,输入天气(温度),可以预测今日的冰淇淋销量、输入患者的信息,可以预测是否有患糖尿病的可能。
更直观一点?
假设今日的温度是x_n,其中n代表的是第n个处理后的温度数据;冰淇淋的销量为y_n,其中n代表的是售出的冰淇淋个数,以下是x-y数据表格。
这是散点图:
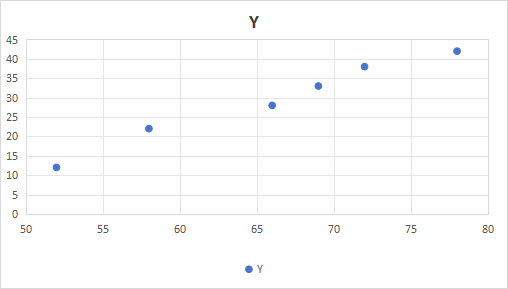
这就可以看出规律了。在这里画一条线:
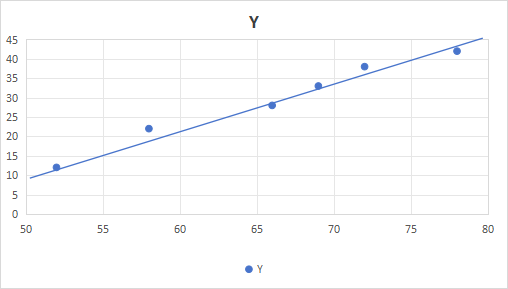
这样就可以预测每个温度大概对应的冰淇淋销量了,例如:
当温度到达75时,预测冰淇淋销量为40个
当然,数据越多时这个函数越准确,而且每种数据都不是像这样一条直线就可以找到规律的。
机器学习的种类
机器学习有很多种类,每种方法都对应着适应的数据。
监督式学习
监督式学习给定特征(例如上文的温度),和标签(例如上文的冰淇淋销量)的数据,训练确定特征和标签之间的关系(温度和冰淇淋销量的规律)。
监督式学习有:
回归
分类
二元分类
多类分类
上文提到的预测冰淇淋销量属于回归。
非监督式学习
非监督式学习仅给定包含特征的数据,预测观测值和特征之间的关系。
如何得出这个函数?
在第二章我将会以线性回归举例,解释如何机器学习是如何训练的